The quest for lifelike Non-Player Characters (NPCs) in modern video games has evolved past rigid finite-state machines and hard-coded behavior trees. Today, the cutting edge of game AI leverages Deep Reinforcement Learning (DRL) via the Unity ML-Agents Toolkit, transforming NPCs into dynamic entities capable of adapting to complex, unpredictable environments.
However, moving from pre-programmed paths to autonomous, self-learning brains introduces deep technical questions: How do neural network architectures shape an NPC’s cognitive capacity? How does position tracking translate into behavioral induction? And most critically, does throwing more compute and advanced GPUs at a model directly result in a “smarter” game agent?
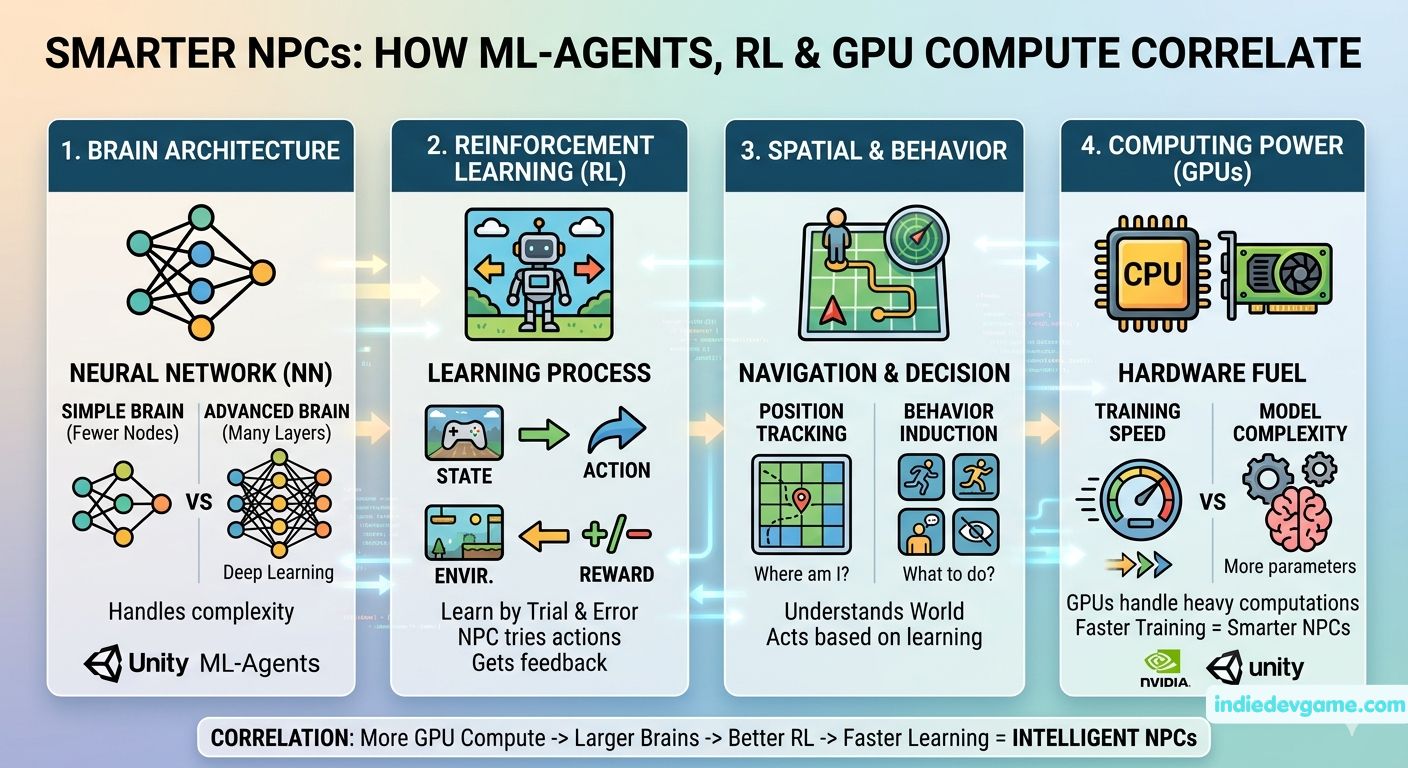
In the context of Unity ML-Agents, an NPC’s “brain” is represented by an Artificial Neural Network (ANN). This architecture acts as a function approximator that maps complex environmental inputs into concrete in-game actions.
How Neural Network Architecture Works
An ANN consists of structured layers of interconnected nodes, or neurons:
The Input Layer: Receives data representing the current state of the game environment (e.g., raycast hits, velocity vectors, or pixel buffers).
Hidden Layers: Positioned between inputs and outputs, these layers perform non-linear transformations on the data. Each connection between nodes across layers has a weight and a bias associated with it. Neurons compute a weighted sum of their inputs, pass it through an activation function (such as ReLU or Swish), and pass the output forward.
The Output Layer: Represents the action space—either discrete actions (e.g., [0] Move Left, [1] Move Right) or continuous values (e.g., a float value between -1.0 and 1.0 for a steering wheel rotation).
The “size” of a network is determined by its depth (number of hidden layers) and its width (number of neurons or hidden units per layer).
Shallow/Narrow Networks: Have fewer parameters. They are computationally lightweight and fast to train, but they suffer from high bias, meaning they lack the capacity to capture intricate structural patterns or complex behavioral strategies.
Deep/Wide Networks: Feature multiple dense hidden layers with high neuron counts. They possess the structural capacity to recognize high-dimensional patterns and formulate long-term strategy, but they are prone to overfitting and require significantly more training data and processing time.
2. How Reinforcement Learning Works
Reinforcement Learning (RL) is a paradigm of machine learning centered on decision-making systems that learn optimal policies through continuous, trial-and-error environmental interactions. The underlying mathematical framework governing this process is the Markov Decision Process (MDP), which models decision-making in non-deterministic environments where outcomes are partly random and partly under the control of the agent.
The core execution loop of RL revolves around four foundational pillars:
Agent: The NPC controller or entity making decisions.
Environment: The game world, physics simulation, or map context.
State (s): The snapshot observation of the environment at a specific time step t.
Action (a): The move executed by the agent, changing the state to st+1.
Reward (r): A scalar feedback value returned by the environment to evaluate the quality of the action taken.
The primary goal of the agent is to find an optimal policy (π)—a mapping from states to actions—that maximizes the expected cumulative future rewards over time, often adjusted by a discount factor (γ) to prioritize immediate versus long-term gains.
In Unity ML-Agents, the default optimization algorithm is Proximal Policy Optimization (PPO). PPO introduces a clipped surrogate objective function that bounds policy updates at each training iteration, preventing destructive policy destabilization and ensuring stable, reliable learning across both discrete and continuous action spaces.
3. Map Tracking, Position, and Inducing Behavior
For an RL agent to function within a game space, it must accurately capture spatial relationships and track its state. In Unity, this tracking is handled via native engine components and sensor scripts, which are then passed directly into the agent’s observation vector.
Methods of Spatial Tracking
Vector Observations: Direct coordinate reading via Transform data (Transform.localPosition, Rigidbody.linearVelocity). The agent observes its exact relative vector to targets, goals, or boundaries.
Raycast Sensors (RaycastSensorComponent3D): Spherical or linear raycasts project outward from the agent at specified angles. They return hit distances and object tags (e.g., “Wall”, “Enemy”, “Item”), acting as a low-cost alternative to complex lidar systems.
Visual Observations (Camera/RenderTexture): Passing raw pixel matrices into the network. While computationally heavy, visual inputs allow agents to interpret spatial depth and occlusions directly from rendering buffers.
Inducing Specific Behavior through Reward Shaping
Behavior is induced entirely by engineering the Reward Function. Because the agent treats the game as a optimization puzzle to maximize cumulative rewards, developers must carefully balance positive reinforcement with negative penalties:
Locomotion & Trajectory: To induce navigation through a complex map, developers implement incremental checkpoint rewards (e.g., awarding +0.5/n per milestone passed) combined with a minor per-step negative penalty (e.g., −0.001) to force the agent to find the fastest path and avoid idling.
Spatial Avoidance: Collisions with hazards, walls, or static obstacles trigger explicit negative penalties (e.g., −0.1) or force an immediate episode termination accompanied by a major negative penalty (e.g., −1.0).
Modular Architectures: For high-fidelity behaviors (like tactical shooter NPCs), monolithic architectures can become uninterpretable or inefficient. Splitting behaviors into semantically distinct, parallel modules—such as a dedicated movement module and a separate combat module—reduces overall retraining times while yielding significantly higher competitive success rates against monolithic baselines.
4. How Neural Networks and RL Intersect
In basic tabular reinforcement learning (like Q-learning), every state-action pair is tracked in a physical matrix. However, when a game environment features continuous movement, infinite physics configurations, or high-dimensional sensory inputs, the state space becomes infinitely large, making tabular mapping impossible.
This is where Deep Reinforcement Learning (DRL) bridges the gap by utilizing neural networks as functional approximators.
In state-of-the-art implementations, Unity ML-Agents relies on an Actor-Critic Architecture. Instead of utilizing a single network, the system splits tasks between two interconnected neural components:
The Actor Network: Takes the current environmental observation (s) as an input and outputs a probability distribution over the available action space (a). It defines the agent’s behavioral policy (πθ).
The Critic Network: Evaluates the state itself. It takes the observation (s) and estimates the absolute expected long-term value (V(s)) of being in that position.
During training, the Critic evaluates whether the agent’s actual reward outcome was better or worse than expected, calculating the Advantage Function:
A(st,at)=Q(st,at)−V(st)
This advantage metric is fed back into the training loop. If the action resulted in a higher advantage than expected, the Actor network adjusts its internal weights to make that specific behavior more likely to occur under similar circumstances in the future.
5. Architectural Examples: Simple vs. Smarter Brains
To configure an agent’s neural capacity in Unity ML-Agents, developers define parameters inside a configuration YAML file under the network_settings block.
Example A: A Simple Brain (Low-Dimensional Tasks)
This setup uses a shallow network structure, perfectly optimized for trivial tracking tasks such as balancing a platform or moving toward a fixed waypoint.
Characteristics: Very fast computation, extremely low memory footprint, but completely incapable of solving environments requiring sequence memory or complex visual routing.
Example B: A Smarter Brain (High-Dimensional / Adaptive Tasks)
This configuration introduces deep, wider layers along with a recurrent neural network component (LSTM) to handle memory over time, making it suitable for dynamic pathfinding or tactical multi-agent combat.
Memory Block (LSTM): Tracks a sequence length of 64 frames, allowing the NPC to remember past positions of targets even when they disappear behind solid walls or geometry.
Characteristics: Capable of synthesizing complex inputs, discovering long-term strategic pathways, and handling high-resolution visual raycasts.
6. Compute Power & Better GPUs: Does it Create “Smarter” NPCs?
The relationship between computing hardware (CPUs, modern GPUs) and ML-Agent training efficiency is highly misunderstood. Developers often assume that running a training pipeline on an enterprise-grade GPU will automatically yield a smarter, more capable NPC. In reality, the correlation behaves non-linearly and is bound by architectural constraints.
The Role of CPU vs. GPU in Unity ML-Agents
Training in Unity is a hybrid process split across two systems:
The Environment Simulation (CPU Bound): The actual game logic, physics steps, raycast calculations, and rendering updates happen natively inside the Unity Engine, which scales heavily with CPU multi-core clock speeds.
The Optimization Loop (GPU Bound): The collection of transition steps, backpropagation, gradient updates, and neural weight adjustments are processed via Python libraries (PyTorch/TensorFlow) on the GPU.
How Scaled Compute Impacts Agent Intelligence
Acceleration of Sample Generation: High-performance GPUs allow developers to radically scale up the num_envs parameter in Unity. Instead of training one agent in one arena, a developer can run 32 or 64 physics environments concurrently. This dramatically accelerates Sample Generation, collecting millions of frames of interaction data in hours instead of days.
Enabling Massive Architectural Complexity: A complex brain (e.g., 3 hidden layers, 512 units, plus an LSTM layer) requires intense floating-point operations per second (FLOPS). Basic compute nodes will bottleneck on these calculations, stalling the training loop. High-tier GPUs allow these massive networks to process large batch sizes (batch_size: 512 or 1024) effortlessly.
The Diminishing Returns Limit
Does advanced compute inherently make an agent smarter? No. Compute power simply buys you speed and capacity.
If an agent’s reward function is poorly shaped, or if the observation space lacks the data required to solve the task, running the environment on multiple enterprise GPUs will simply allow the agent to fail millions of times faster. True NPC “intelligence” is a delicate trade-off: excessive input dimensionality (such as overly high-resolution camera feeds) or bloated network widths can actually over-complicate the observation space, resulting in drastically slower policy convergence and erratic, unoptimized behavior. Compute power acts as the fuel, but the neural network design and reward logic remain the engine of true machine intelligence.
🚀 Ready to Build Your Own Intelligent NPCs?
Now that you understand how neural architectures, reinforcement learning, and GPU compute power correlate to create advanced AI, it’s time to get your hands dirty.
To transition from high-level theory to actual implementation, check out the foundational guide: ML-Agents in Unity: Definitive Guide – Basic Concepts. This step-by-step primer covers core training loops, setting up your first observation vectors, and mastering the essential terminology needed to launch your first brain.
Unity Simulation Environments: Juliani, A., Berges, V., Teng, E., Cohen, A., Harper, J., Elion, C., Goy, C., Gao, Y., Henry, H., Mattar, M., & Lange, D. (2018). Unity: A General Platform for Intelligent Agents. arXiv preprint arXiv:1809.02626.